Apache Kafka often serves as a central component in the overall data architecture with other systems pumping data into it. But, data in Kafka (topics) is only useful when consumed by other applications or ingested into other systems. Although, it is possible to build a solution using the Kafka Producer/Consumer APIs using a language and client SDK of your choice, there are other options in the Kafka ecosystem.
One of them is Kafka Connect, which is a platform to stream data between Apache Kafka and other systems in a scalable and reliable manner. It supports several off the shelf connectors, which means that you don't need custom code to integrate external systems with Apache Kafka.
This article will demonstrate how to use a combination of Kafka connectors to set up a data pipeline to synchronize records from a relational database such as PostgreSQL in real-time to Azure Cosmos DB Cassandra API.
The code and config for this application is availablei in this GitHub repo - https://github.com/abhirockzz/postgres-kafka-cassandra
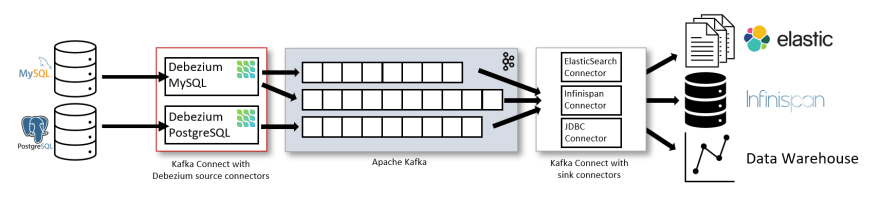
Here is a high-level overview ...
... of the end to end flow presented in this article.
Operations against the data in PostgreSQL table (applies to INSERTs for this example) will be pushed to a Kafka topic as change data events, thanks to the Debezium PostgreSQL connector that is a Kafka Connect source connector - this is achieved using a technique called Change Data Capture (also known as CDC).
Change Data Capture: a quick primer
It is a technique used to track row-level changes in database tables in response to create, update and delete operations. This is a powerful capability, but useful only if there is a way to tap into these event logs and make it available to other services which depend on that information.
Debezium is an open-source platform that builds on top of Change Data Capture features available in different databases. It provides a set of Kafka Connect connectors which tap into row-level changes (using CDC) in database table(s) and convert them into event streams. These event streams are sent to Apache Kafka. Once the change log events are in Kafka, they will be available to all the downstream applications.
This is different compared to the "polling" technique adopted by the Kafka Connect JDBC connector
The diagram (from the debezium.io website) summarises it nicely!
Part two
In the second half of the pipeline, the DataStax Apache Kafka connector (Kafka Connect sink connector) synchronizes change data events from Kafka topic to Azure Cosmos DB Cassandra API tables.
Components
This example provides a reusable setup using Docker Compose. This is quite convenient since it enables you to bootstrap all the components (PostgreSQL, Kafka, Zookeeper, Kafka Connect worker, and the sample data generator application) locally with a single command and allow for a simpler workflow for iterative development, experimentation etc.
Using specific features of the DataStax Apache Kafka connector allows us to push data to multiple tables. In this example, the connector will help us persist change data records to two Cassandra tables that can support different query requirements.
Here is a breakdown of the components and their service definitions - you can refer to the complete docker-compose file in the GitHub repo.
- Kafka and Zookeeper use debezium images.
- The Debezium PostgreSQL Kafka connector is available out of the box in the debezium/connect Docker image!
- To run as a Docker container, the DataStax Apache Kafka Connector is baked on top the debezium/connect image. This image includes an installation of Kafka and its Kafka Connect libraries, thus making it really convenient to add custom connectors. You can refer to the Dockerfile.
- The
data-generatorservice seeds randomly generated (JSON) data into theorders_infotable in PostgreSQL. You can refer to the code andDockerfilein the GitHub repo
You will need to...
- Install Docker and Docker Compose.
- Provision an Azure Cosmos DB Cassandra API account
- Use cqlsh or hosted shell for validation
Start off by creating Cassandra Keyspace and tables
Use the same Keyspace and table names as below
CREATE KEYSPACE retail WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 1};
CREATE TABLE retail.orders_by_customer (order_id int, customer_id int, purchase_amount int, city text, purchase_time timestamp, PRIMARY KEY (customer_id, purchase_time)) WITH CLUSTERING ORDER BY (purchase_time DESC) AND cosmosdb_cell_level_timestamp=true AND cosmosdb_cell_level_timestamp_tombstones=true AND cosmosdb_cell_level_timetolive=true;
CREATE TABLE retail.orders_by_city (order_id int, customer_id int, purchase_amount int, city text, purchase_time timestamp, PRIMARY KEY (city,order_id)) WITH cosmosdb_cell_level_timestamp=true AND cosmosdb_cell_level_timestamp_tombstones=true AND cosmosdb_cell_level_timetolive=true;
Use Docker Compose to start all the services
git clone https://github.com/abhirockzz/postgres-kafka-cassandra
cd postgres-kafka-cassandra
As promised, use a single command to start all the services for the data pipeline:
docker-compose -p postgres-kafka-cassandra up --build
It might take a while to download and start the containers: this is just a one time process.
Check whether all the containers have started. In a different terminal, run:
docker-compose -p postgres-kafka-cassandra ps
The data generator application will start pumping data into the orders_info table in PostgreSQL. You can also do quick sanity check to confirm. Connect to your PostgreSQL instance using psql client...
psql -h localhost -p 5432 -U postgres -W -d postgres
when prompted for the password, enter
postgres
... and query the table:
select * from retail.orders_info;
At this point, all you have is PostgreSQL, Kafka and an application writing random data to PostgreSQL. You need to start the Debezium postgreSQL connector to send the PostgreSQL data to a Kafka topic.
Start PostgreSQL connector instance
Save the connector configuration (JSON) to a file example pg-source-config.json
{
"name": "pg-orders-source",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "postgres",
"database.password": "password",
"database.dbname": "postgres",
"database.server.name": "myserver",
"plugin.name": "wal2json",
"table.include.list": "retail.orders_info",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
}
}
To start the PostgreSQL connector instance:
curl -X POST -H "Content-Type: application/json" --data @pg-source-config.json http://localhost:9090/connectors
To check the change data capture events in the Kafka topic, peek into the Docker container running the Kafka connect worker:
docker exec -it postgres-kafka-cassandra_cassandra-connector_1 bash
Once you drop into the container shell, just start the usual Kafka console consumer process:
cd ../bin
./kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic myserver.retail.orders_info --from-beginning
Note that the topic name is
myserver.retail.orders_infowhich as per the connector convention
You should see the change data events in JSON format.
So far so good! The first half of the data pipeline seems to be working as expected. For the second half, we need to...
Start DataStax Apache Kafka connector instance
Save the connector configuration (JSON) to a file example, cassandra-sink-config.json and update the properties as per your environment.
{
"name": "kafka-cosmosdb-sink",
"config": {
"connector.class": "com.datastax.oss.kafka.sink.CassandraSinkConnector",
"tasks.max": "1",
"topics": "myserver.retail.orders_info",
"contactPoints": "<Azure Cosmos DB account name>.cassandra.cosmos.azure.com",
"loadBalancing.localDc": "<Azure Cosmos DB region e.g. Southeast Asia>",
"datastax-java-driver.advanced.connection.init-query-timeout": 5000,
"ssl.hostnameValidation": true,
"ssl.provider": "JDK",
"ssl.keystore.path": "<path to JDK keystore path e.g. <JAVA_HOME>/jre/lib/security/cacerts>",
"ssl.keystore.password": "<keystore password: it is 'changeit' by default>",
"port": 10350,
"maxConcurrentRequests": 500,
"maxNumberOfRecordsInBatch": 32,
"queryExecutionTimeout": 30,
"connectionPoolLocalSize": 4,
"auth.username": "<Azure Cosmos DB user name (same as account name)>",
"auth.password": "<Azure Cosmos DB password>",
"topic.myserver.retail.orders_info.retail.orders_by_customer.mapping": "order_id=value.orderid, customer_id=value.custid, purchase_amount=value.amount, city=value.city, purchase_time=value.purchase_time",
"topic.myserver.retail.orders_info.retail.orders_by_city.mapping": "order_id=value.orderid, customer_id=value.custid, purchase_amount=value.amount, city=value.city, purchase_time=value.purchase_time",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"offset.flush.interval.ms": 10000
}
}
Start the connector:
curl -X POST -H "Content-Type: application/json" --data @cassandra-sink-config.json http://localhost:8080/connectors
If everything has been configured correctly, connector will start pumping data from Kafka topci into Cassandra table(s) and our end to end pipeline will be operational.
You'd obviously want to ...
Query Azure Cosmos DB
Check the Cassandra tables in Azure Cosmos DB. If you have cqlsh installed locally, you can simply use it as such:
export SSL_VERSION=TLSv1_2 &&\
export SSL_VALIDATE=false &&\
cqlsh.py <cosmosdb account name>.cassandra.cosmos.azure.com 10350 -u kehsihba-cassandra -p <cosmosdb password> --ssl
Here are some of the queries you can try:
select count(*) from retail.orders_by_customer;
select count(*) from retail.orders_by_city;
select * from retail.orders_by_customer;
select * from retail.orders_by_city;
select * from retail.orders_by_city where city='Seattle';
select * from retail.orders_by_customer where customer_id = 10;
Conclusion
To summarize, you learnt how to use Kafka Connect for real-time data integration between PostgreSQL, Apache Kafka and Azure Cosmos DB. Since the sample adopts a Docker container based approach, you can easily customise this as per your own unique requirements, rinse and repeat!
The following topics might also be of interest...
If you found this useful, you may also want to explore the following resources:
- Migrate data from Oracle to Azure Cosmos DB Cassandra API using Blitzz
- Migrate data from Cassandra to Azure Cosmos DB Cassandra API account using Azure Databricks
- Quickstart: Build a Java app to manage Azure Cosmos DB Cassandra API data (v4 Driver)
- Apache Cassandra features supported by Azure Cosmos DB Cassandra API
- Quickstart: Build a Cassandra app with Python SDK and Azure Cosmos DB


















